🔍 Key Observation 1: Not All Layers Matter in Video Customization
By analyzing the effects of injecting text embeddings p and p* across different layers of the U-Net, our experiments demonstrate that for appearance customization, text embedding injection solely at layers 2 and 6 achieves comparable results to full-layer injection.
p="A koala" p*="A tiger"
$$V_{p^{*} \rightarrow i\neq 6, p \rightarrow j\neq i}$$
$$V_{p^{*} \rightarrow i=6, p \rightarrow j\neq i}$$
$$V_{p^{*} \rightarrow i=2,6, p \rightarrow j\neq i}$$
$$V_{p^{*} \rightarrow all}$$
For motion, injecting the text embedding into only layers 2 and 4 can achieve the effect of injecting it into all layers.
p="A dog is swimming" p*="A dog is running"
$$V_{p^{*} \rightarrow i\neq 2, p \rightarrow j\neq i}$$
$$V_{p^{*} \rightarrow i=2, p \rightarrow j\neq i}$$
$$V_{p^{*} \rightarrow i=2,4, p \rightarrow j\neq i}$$
$$V_{p^{*} \rightarrow all}$$
💡 Key Observation 2: Test-Time Training Improves Concept Combination
Directly combining the pre-trained spatial LoRA and temporal LoRA for inference can lead to issues such as text-video inconsistency and artifacts in the generated results. Therefore, it is necessary to introduce an additional Test-Time Training phase to reduce the distribution gap between the two, thereby improving the quality of the generated video.







A teedy bear is playing guitar on the snow.


A teedy bear is playing guitar on the Mars.
Method
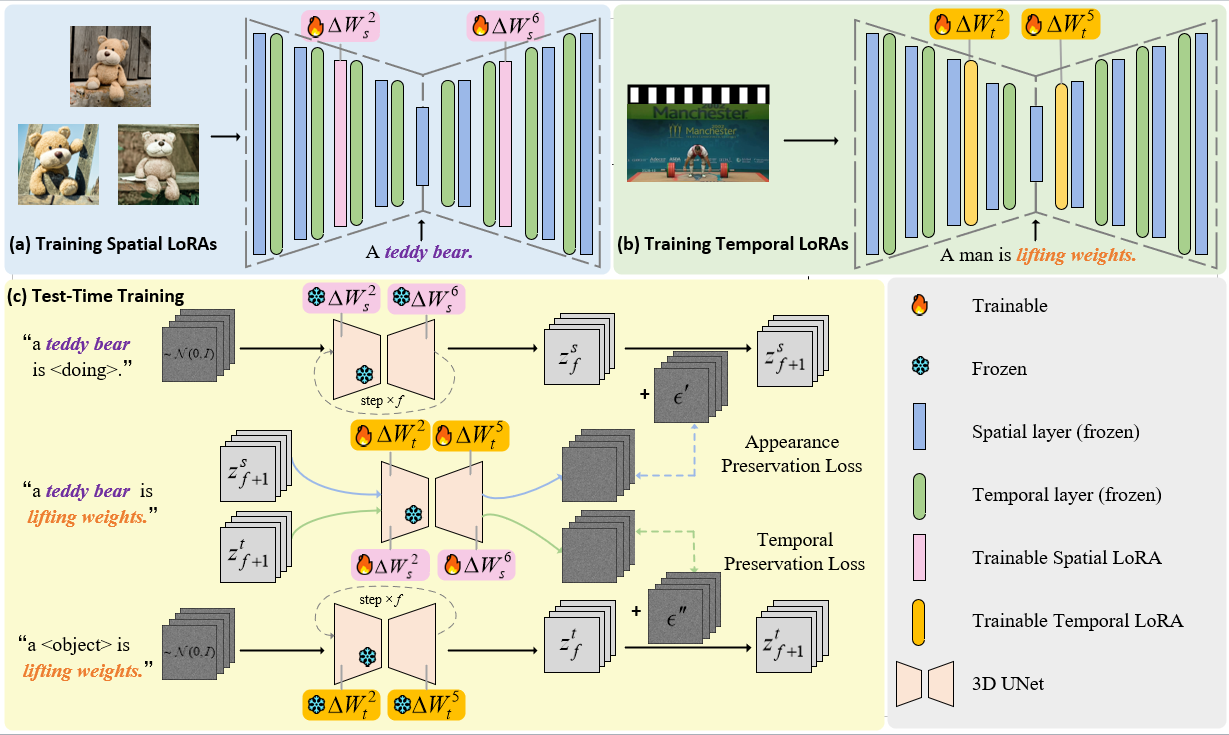
The overall pipeline. We first train the LoRAs on the specific layers for appearance (a) and motion (b) customization individually. Then, we design a test-time training method to further improve the results when combining.
Comparison with SOTA
Qualitative comparison of customized video generation with both subjects and motions.
Without
guidance from additional videos, our method significantly outperforms in terms of concept combination.
References
[1] Wei, Yujie, et al. "Dreamvideo: Composing your dream videos with customized subject and motion." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[2] Zhao, Rui, et al. "Motiondirector: Motion customization of text-to-video diffusion models." European Conference on Computer Vision. Springer, Cham, 2025.
BibTeX
@article{wu2024customttt,
title={CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training},
author={Bi, Xiuli and Lu, Jian and Liu, Bo and Cun, Xiaodong and Zhang, Yong and Li, WeiSheng and Xiao, Bin},
journal={arXiv preprint arXiv:2412.15646},
year={2024}
}